
Substrate-Agnostic Cognitive Architecture
Closing the Gap Between Brain Science and Deployable Cognitive Systems

Abstract
Decades of neuroscience have established that the brain is a collection of functionally distinct regions with identifiable inputs, outputs, and computational roles. Simultaneously, machine learning has produced high-quality implementations of many of those functions in isolation. Yet no research program has combined both observations into their logical conclusion: a working cognitive system assembled from best-fit substrate per region, coordinated over a shared event bus, with no requirement for biological fidelity. Existing efforts fail in one of several ways. They are substrate-committed, demanding biological tissue or homogeneous tensor compute, or they are architecturally faithful but fill every module with the same kind of model. A fourth failure mode is the from-scratch neurosymbolic approach, which correctly identifies the learning problem but solves it by rebuilding everything rather than composing what already exists. This paper characterizes the gap, surveys what is known about each major functional region, proposes clean interface contracts between regions, and outlines the minimum credible path to a working proof of concept. The required work is an engineering problem, not a scientific one, and it is tractable with a small team and seed-scale funding.
Keywords: cognitive architecture, modular AI systems, neuromorphic computing, heterogeneous compute, AGI systems design, whole brain emulation, functional brain modeling, multi-agent systems, event-driven architecture, neurosymbolic AI
1. Introduction
The modular organization of the brain is not a hypothesis. Lesion studies, split-brain experiments, and decades of functional imaging have produced a detailed circuit diagram of which regions handle what. Visual processing, episodic encoding, motor sequencing, executive planning, reward learning, and routing between them are all separable. Damage to one region produces specific, predictable deficits. The system is not homogeneous.
Machine learning has, in parallel, produced strong implementations of many of these functions. Convolutional and transformer architectures match or exceed human performance on visual recognition. Large language models handle reasoning, planning, and language production at a level that was not expected this decade. Reinforcement learning systems learn reward-driven behavior. Vector databases provide fast associative retrieval. These are not approximations. For their target functions, they work.
The logical synthesis is clear: treat each brain region as a functional specification, implement it with whatever substrate best fits its computational profile, define clean interfaces between regions, and wire them together. Nobody has done this. This paper asks why, characterizes the current gap in the literature, and proposes the minimum viable path forward.
2. Why Existing Approaches Fall Short
2.1 Substrate-committed simulation
The Human Brain Project and the Blue Brain Project pursue biological fidelity as a primary goal. Every neuron is modeled, every spike is simulated. This produces scientifically interesting output but is not a path to a working cognitive system on any near-term timescale. Fidelity and function are different targets. A perfect simulation of a wing does not fly.
2.2 Substrate-committed hardware
Neuromorphic programs such as Intel Loihi and IBM TrueNorth commit to spike-based computation as a substrate principle. This is appropriate for some functions and entirely inappropriate for others. Spike-based computation is not a good substrate for large-scale language modeling. Choosing a substrate first and fitting the function to it inverts the correct design order.
2.3 Homogeneous ML architectures
Brain-inspired cognitive architectures in the ML literature, including work on modular agentic planners and cognitive architecture as a service, correctly decompose the problem into functional regions. They then implement every region with the same model type, typically a large language model or a standard neural network. This abandons the efficiency and appropriateness gains that motivated the decomposition in the first place. A cerebellum implemented as a 70B parameter language model is not a cerebellum. It is a language model doing a poor impression of one.
2.4 Neurosymbolic from-scratch approaches
Systems such as Voss’s integrated neurosymbolic architecture represent the closest conceptual alignment with the argument made here. They correctly identify that frozen statistical models cannot perform real-time incremental learning, correctly reject the patch-an-LLM approach, and correctly center knowledge representation as the architectural backbone rather than an afterthought. The result is a system capable of one-shot learning, ontological rather than statistical knowledge structure, and genuine metacognition.
The failure mode is not conceptual but strategic. Building every cognitive mechanism from scratch, including the knowledge graph, the learning engine, the reasoning layer, and the language interface, in a single integrated system requires rebuilding what already exists at considerable cost and over a long timeline. Two decades and a team of ten is the demonstrated consequence. The insight that learning must be continuous and ontological is correct and worth preserving. The conclusion that this requires a wholly new system built from the ground up does not follow. The hippocampal and neocortical modules in the architecture proposed here can use a high-performance vector knowledge graph as their substrate, gaining exactly the properties Voss identifies, while the surrounding modules use best-fit existing implementations. The learning problem is real. The solution does not require starting from zero.
2.5 The whole brain architecture exception
The Whole Brain Architecture initiative in Japan is the closest existing approach to what this paper proposes. It separates the reference architecture from the component implementations and develops them independently. It remains underfunded and underrepresented in Western research discourse, and has not produced a working integrated system at time of writing.
The gap is not scientific. We know what each region does. The gap is that nobody has treated this as a systems engineering project with appropriate interface discipline.
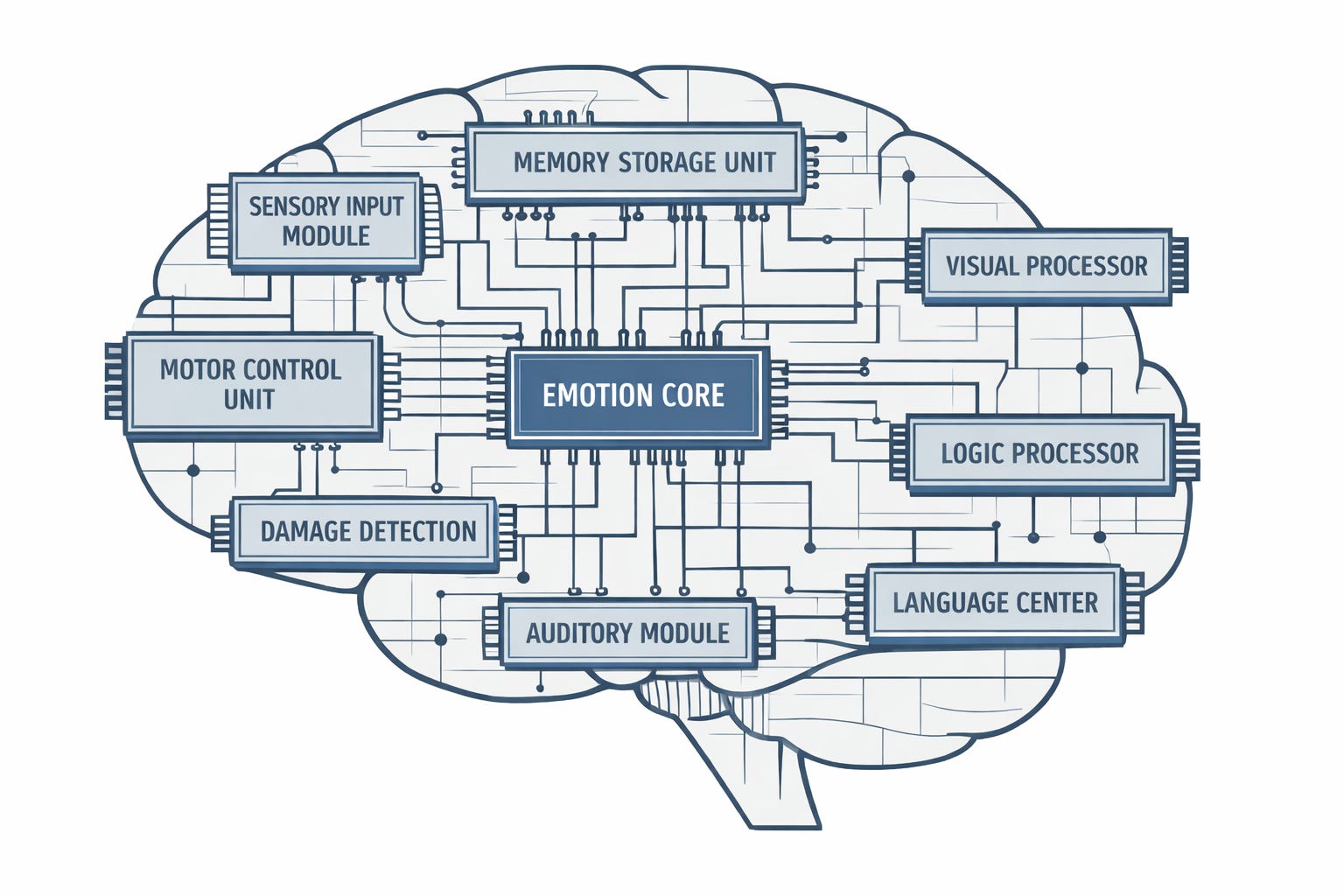
3. Functional Specifications by Region
Each region below is described in terms of its functional role, what it takes as input, what it produces as output, and the proposed implementation substrate. Biological fidelity is not a requirement at any point.
The visual cortex, from V1 to inferotemporal cortex, performs hierarchical feature extraction and object recognition. It takes raw pixel arrays and depth maps as input and produces object tokens and a scene graph. A convolutional or vision transformer architecture handles this. It is a solved problem.
The auditory cortex handles sound segmentation and phoneme extraction. Input is raw audio. Output is phoneme sequences and speaker embeddings. A Whisper-class model handles this. Also solved.
The hippocampus performs fast one-shot episodic binding and maintains an index for neocortical replay. It takes multi-modal event representations as input and produces episode identifiers and retrieval cues. The appropriate substrate is a vector knowledge graph with a write scheduler. Consolidation runs on a clock, not continuously.
The neocortex, specifically the sensory and association areas, handles slow-learning general representations and generalization across episodes. It takes replayed episodes from the hippocampus and produces updated weight states and semantic embeddings. A fine-tunable transformer with scheduled consolidation passes serves this role. This is the offline learning loop.
The prefrontal cortex handles working memory, planning, goal maintenance, and tool selection. Input is the current context, goal state, and available tools. Output is action selection and subgoal decomposition. A large language model with extended context and tool-use scaffolding covers this function for a wide range of tasks.
The basal ganglia handle action selection via reward-weighted competition and habit formation. They take candidate actions and a reward signal as input and produce a selected action and updated action weights. A reinforcement learning module covers this, either standard deep RL or a lightweight bandit depending on the action space.
The cerebellum handles timing, error correction, and fine motor prediction. It takes an intended action and sensory feedback as input and produces a correction signal. Classical ML, a PID controller, or a lightweight recurrent network is appropriate. This is not a problem that requires a language model.
The thalamus handles dynamic routing between regions, attention gating, and arousal modulation. It takes system state, attention priorities, and sensory load as input and produces a routing table and bandwidth allocation per channel. A lightweight learned router handles this. It is the hardest module to specify cleanly but not the hardest to implement once the spec exists.
The amygdala handles salience tagging, threat flagging, and emotional valence assignment. It takes an incoming percept or memory and produces a salience score and valence tag. A classifier or learned scoring function covers this. Its outputs feed into thalamic routing priority.
The anterior cingulate handles conflict monitoring, error detection, and resource allocation. It takes competing outputs from multiple modules and produces a conflict signal and an attention redirect. A consistency checker running over the event bus handles this, flagging disagreements between modules for prefrontal arbitration.
4. The Integration Layer
The correct solution to the joining problem is not to specify every module-to-module interface individually. That produces a brittle web of bilateral contracts that breaks when any module changes. The correct solution, already identified in the cognitive architecture literature and standard in distributed systems engineering, is a shared event bus.
Every module publishes typed events to the bus. Every module subscribes to the event types it needs. The bus format is the only interface that must be stable. Individual modules can change their internal implementation freely as long as they continue to emit and consume the agreed event schema.
Apache Kafka or a lighter equivalent such as NATS serves this role. The thalamic router is then not a separate piece of infrastructure. It is a routing policy applied to the bus that controls which subscriptions receive which event types under which system states. Arousal state, attentional priority, and sensory load adjust the routing policy dynamically. This is a software configuration problem, not a neuroscience problem.
5. The Learning Loop
The most common objection to frozen model architectures as cognitive components is that they cannot learn from experience. This objection is correct but does not imply the architecture is unworkable. It implies a consolidation schedule.
The brain does not learn continuously either. Synaptic consolidation during sleep, memory replay, and the slow transfer from hippocampal index to neocortical generalization all happen on a delayed schedule. Memories fade, get rewritten, and drift. This is a feature. It prevents catastrophic interference and produces generalization rather than memorization.
The engineering equivalent is a periodic consolidation job. The hippocampal vector store accumulates episodes during operation. The consolidation scheduler selects episodes for replay, generates fine-tuning data, and updates the neocortical model weights. This is not online learning in the strict sense. It is the same learning loop the brain runs, implemented on a clock rather than in continuous biological time.
Catastrophic forgetting during fine-tuning is a real concern but a solved engineering problem. Elastic weight consolidation, low-rank adaptation, and replay-based training all constrain weight updates to preserve prior generalizations.
6. Tool Use and Agency
The prefrontal module in this architecture is already the most mature component. Large language models with tool-use scaffolding, code execution environments, browser access, and file system interaction represent a working implementation of executive function for a wide range of tasks. The work on agents with terminals, API access, and multi-step planning is active and producing usable systems.
What the current agent literature lacks is the surrounding architecture. An LLM agent with tool access has no sensory processing pipeline feeding it, no salience system prioritizing its inputs, no habit system offloading routine actions, and no consolidation loop updating its generalizations from experience. It is a prefrontal lobe with no rest of the brain attached. Adding the surrounding modules does not require replacing the agent. It requires wiring it into the bus as one subscriber among several.
7. Minimum Viable Path
Step one is writing the interface specification, which should take one to two months. This means defining the event schema for the shared bus and specifying the input and output types for each module. This document is the core deliverable of phase one and the only thing all subsequent work depends on. It does not require any running code.
Step two is implementing the bus and the prefrontal module, covering roughly months two through four. Stand up the event bus, wire an existing LLM agent into it as the prefrontal module, and validate that the bus handles the throughput and latency requirements for real-time operation. At this point the system does what an LLM agent already does, but on an architecture that can accept additional modules.
Step three is adding the hippocampal and thalamic modules, from month four through month eight. This is the first point at which the system exceeds what existing agent architectures provide. The vector knowledge graph gives episodic memory that persists across sessions. The router begins directing traffic between modules based on system state. The consolidation scheduler runs its first test passes.
Step four is adding the sensory and basal ganglia modules, from month eight through month fourteen. Vision, audio, and a reward-based action selector join the bus. The system can now receive real-world percepts, assign salience, route them to the appropriate processing modules, and select among competing actions based on learned reward history. The first evaluation of cross-module coherence happens here.
Step five is evaluation and publication of the proof of concept, from month fourteen through month eighteen. The relevant question is not whether the system matches a brain but whether it outperforms a homogeneous agent on tasks that require the combined operation of multiple functional modules: tasks with perceptual input, episodic memory requirements, habit-eligible sub-tasks, and novel executive decisions in the same session.
8. Resource Requirements
Hardware costs to proof of concept sit in the range of $2 to 4M for GPU compute covering the prefrontal and sensory modules, using existing model weights with no pretraining required. Storage and vector infrastructure adds $300 to 500K. Networking and bus infrastructure adds another $200 to 400K.
The core engineering team of five to eight people over eighteen months costs $4 to 6M. These are systems engineers and ML engineers, not neuroscientists. Functional consultants with neuroscience backgrounds, two to three people working part time as spec writers rather than implementers, add $600K to 1M.
Total to a credible proof of concept is $7 to 12M. That is standard seed to Series A range, cheaper than most biotech, vastly cheaper than a frontier model lab, and cheaper than a semiconductor startup.
9. What This Does Not Solve
This proposal targets a working cognitive system with memory, perception, planning, and learned behavior. It does not address subjective experience and does not claim to. The question of whether such a system has any form of experience is not one this architecture answers in either direction, and it is not a requirement for the system to be useful or interesting.
The consolidation loop produces learning that generalizes over time but does not produce within-session weight updates. A single interaction that should fundamentally change the system’s behavior will not do so until the next consolidation pass. This is a limitation shared with the biological original, but it is a real limitation for applications requiring immediate adaptation.
The thalamic routing module requires a learned policy for which there is no obvious pre-existing training set. Building and evaluating this policy is likely the hardest single engineering task in the roadmap above.
10. Conclusion
The brain is a collection of parts. We know what the parts do. We have good implementations of most of them. The gap between that knowledge and a working assembled system is an engineering gap, not a scientific one. It has persisted because existing research programs are committed to their substrates and their homogeneous architectures rather than to function as the primary specification. Neurosymbolic approaches identify the right problems but solve them by rebuilding from scratch rather than composing what exists.
A substrate-agnostic, interface-first, systems-engineering approach to cognitive architecture is tractable with current technology, a small team, and seed-scale funding. The first milestone is not a working mind. It is a working bus with two modules on it. Everything after that is integration.
References
Markram, H. et al. (2015). Reconstruction and simulation of neocortical microcircuitry. Cell, 163(2), 456-492.
Davies, M. et al. (2018). Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro, 38(1), 82-99.
Hawkins, J. and Blakeslee, S. (2004). On Intelligence. Times Books.
Ketz, N. et al. (2013). Thalamic pathways underlying prefrontal cortex-medial temporal lobe oscillatory interactions. Trends in Neurosciences, 38(1), 3-12.
Kumaran, D., Hassabis, D., and McClelland, J.L. (2016). What learning systems do intelligent agents need? Complementary learning systems theory updated. Trends in Cognitive Sciences, 20(7), 512-534.
Stocco, A. et al. (2021). Empirical evidence for a role of the basal ganglia in the control of working memory. Neuropsychology, 35(2), 181.
Zador, A. et al. (2023). Toward next-generation artificial intelligence: catalyzing the NeuroAI revolution. Nature Communications, 14, 1597.
Yamakawa, H. (2021). Whole brain architecture approach: accelerating the development of artificial general intelligence by referring to the brain. Procedia Computer Science, 71.
Kirkpatrick, J. et al. (2017). Overcoming catastrophic forgetting in neural networks. PNAS, 114(13), 3521-3526.
Hu, E. et al. (2021). LoRA: Low-rank adaptation of large language models. arXiv:2106.09685.
Voss, P. (2025). The future of AI and AGI. Invited talk. Cognitive AI / Aigo.
Very interesting if I understood it.
Very interesting post. I been following agentic frameworks and started building agentic scaffolding of my own.
You presented it as a clean and straightforward AGI architecture . It seems right now all the pieces are solved and its just about putting it together.
As solution is obvious, its probably being built and tested right now. I have a feeling we will see these in public soon enough.
I started digging into langgraph as possible general framework, but its focus is relatively narrow